
My Fairy Story with GenAI

Elina Canavady





Our student projects showcase the incredible innovation of young minds guided by expert instruction. From mobile apps that help the visually impaired navigate safely to AI systems that detect emotions and respond with appropriate music, our students are already making a difference in the world.










Rated 4.7 out of 5 based on 44reviews on Trustpilot


Upon successful completion of our course, you are entitled to get a certificate from us.
Easy and direct!
We have a simple approach to enrolment. You can schedule a free assessment lesson, and after the session, you get a recommendation for a course that fits you the best. You will be asked to decide on the class format, and classes will be scheduled shortly based on your convenience. If you choose a Robotics course, the STEM kit will be shipped to you.
Everything we both need to know!
You need to let us know the preferred course. If you are not sure, we will recommend the course that suits you. The instructor demonstrates the course in an approximately one-hour online session. This will be a “get to know” session and is used to evaluate the level of understanding of the child so that we can recommend a suitable course. As a parent, you can find answers to your queries regarding the course structure and curriculum. A recommendation from the instructor will be sent to you soon after to help you decide on the course.
From basics to advanced, and even customized!
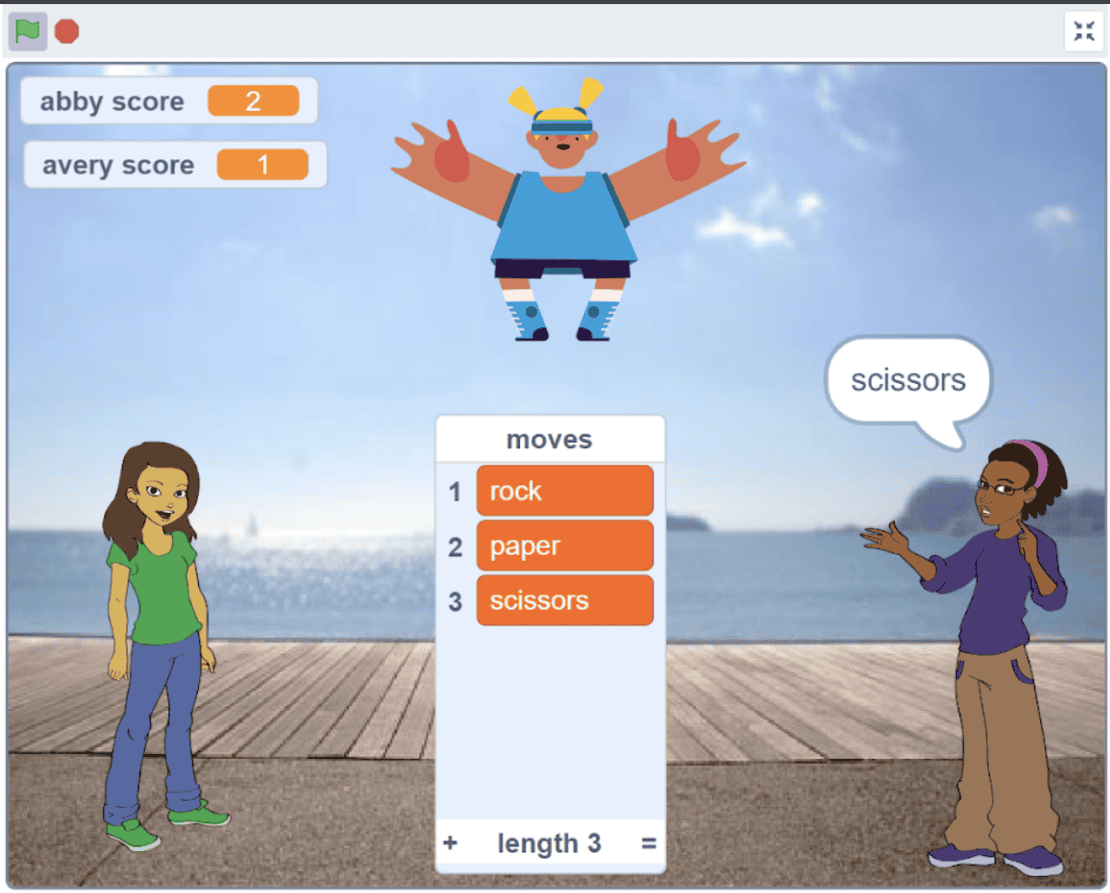
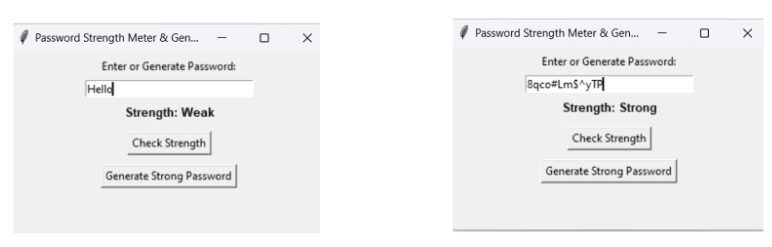
We offer live, 1-1, or 1-2, and group coding classes. You can choose the format once you decide to enroll. We offer an age-oriented approach, in the course, we cover programming fundamentals and transition to advanced concepts depending on the capabilities of the kids. There are courses in Scratch, App Building, and Python.
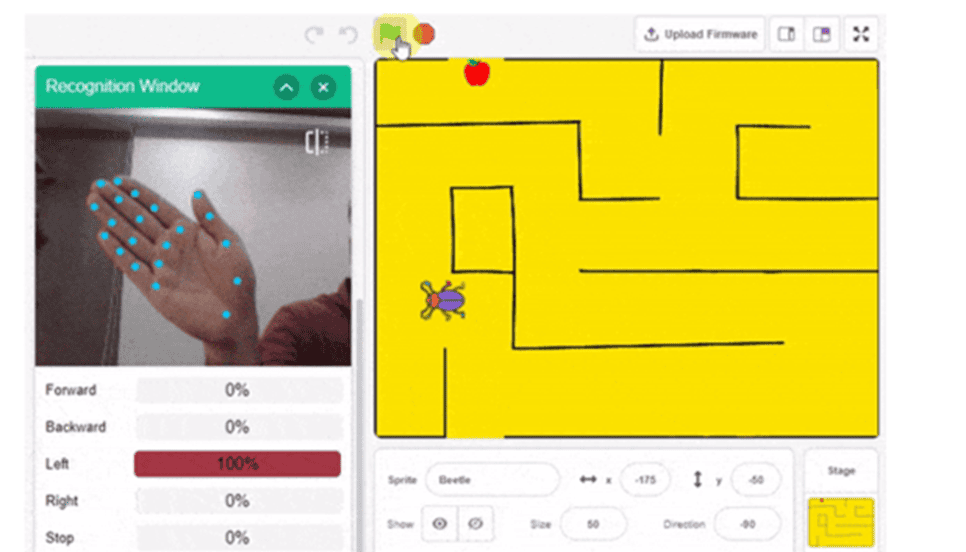
Activity-oriented it is!
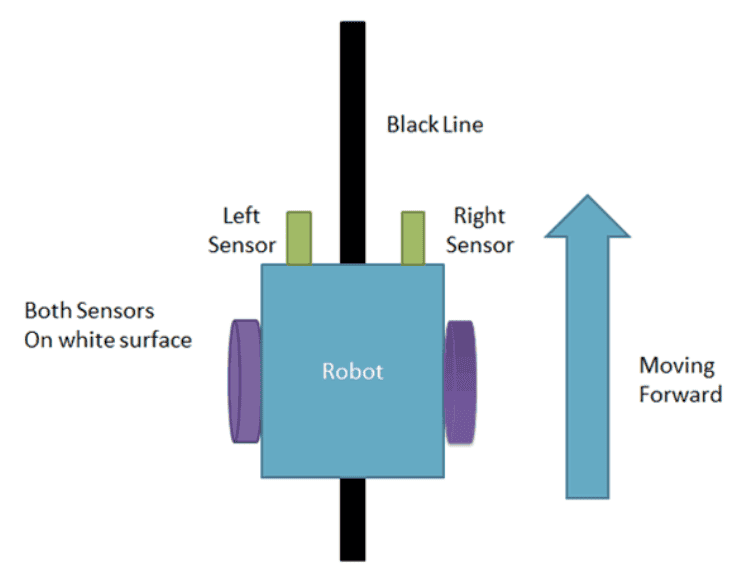
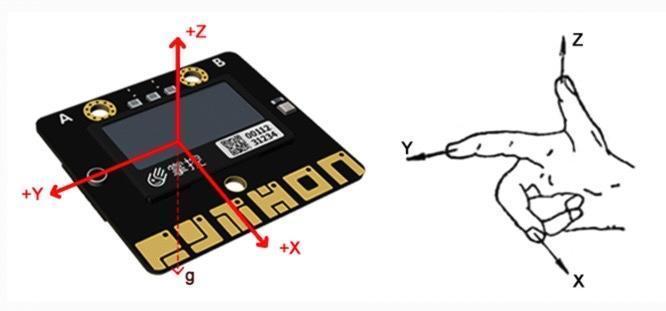
Unlike our software courses, in this course, we use visually appealing hardware modules and extensions to make learning more activity oriented. Kids learn to program the robots with Scratch and Python. We offer live, 1-1 or 1-2, and group Robotics classes.
We will give our best to you!
Our teachers are selected after multiple rounds of screening and interviews. Teachers go through a five-step selection process with a selection rate of 3%. They also undergo a one-month rigorous training before they start. Teachers regularly attend workshops conducted by professionals and are mentored throughout the process.
Looking forward to collaborating?
Our group classes (maximum size 6) are prescheduled for two days a week. If you prefer them, please contact us, and we can guide you through the process.
Age can’t decide anything. Can it?
Our courses start at age 5. We believe that age is not a barrier to learning. We have a range of course options suiting your age and coding background. We also have courses for adults looking for a career switch with Python.
We are an online academy and do not provide physical classes currently.
Definitely!
We encourage them to participate in contests worldwide. We also organize competitions to prepare our students for challenges.
That makes learning more fun!
Yes, kids are encouraged to design and build their own projects. The instructors provide project ideas after every 10 sessions and ask the kids to develop them. There are assignments and regular homework in addition to projects to encourage self-learning.

